Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility
Code arXiv HuggingFace Model OutputsAbstract
While synthetic data has proven effective for improving scientific reasoning in the text domain, multimodal reasoning remains constrained by the difficulty of synthesizing scientifically rigorous images. Existing Text-to-Image (T2I) models often produce outputs that are visually plausible yet scientifically incorrect, resulting in a persistent visual–logic divergence that limits their value for downstream reasoning. Motivated by recent advances in next-generation T2I models, we conduct a systematic study of scientific image synthesis across generation paradigms, evaluation, and downstream use. We analyze both direct pixel-based generation and programmatic synthesis, and propose ImgCoder, a logic-driven framework that follows an explicit “understand → plan → code” workflow to improve structural precision. To rigorously assess scientific correctness, we introduce SciGenBench, which evaluates generated images based on information utility and logical validity. Our evaluation reveals systematic failure modes in pixel-based models and highlights a fundamental expressiveness–precision trade-off. Finally, we show that fine-tuning Large Multimodal Models (LMMs) on rigorously verified synthetic scientific images yields consistent reasoning gains, with potential scaling trends analogous to the text domain, validating high-fidelity scientific synthesis as a viable path to unlocking massive multimodal reasoning capabilities.
Method
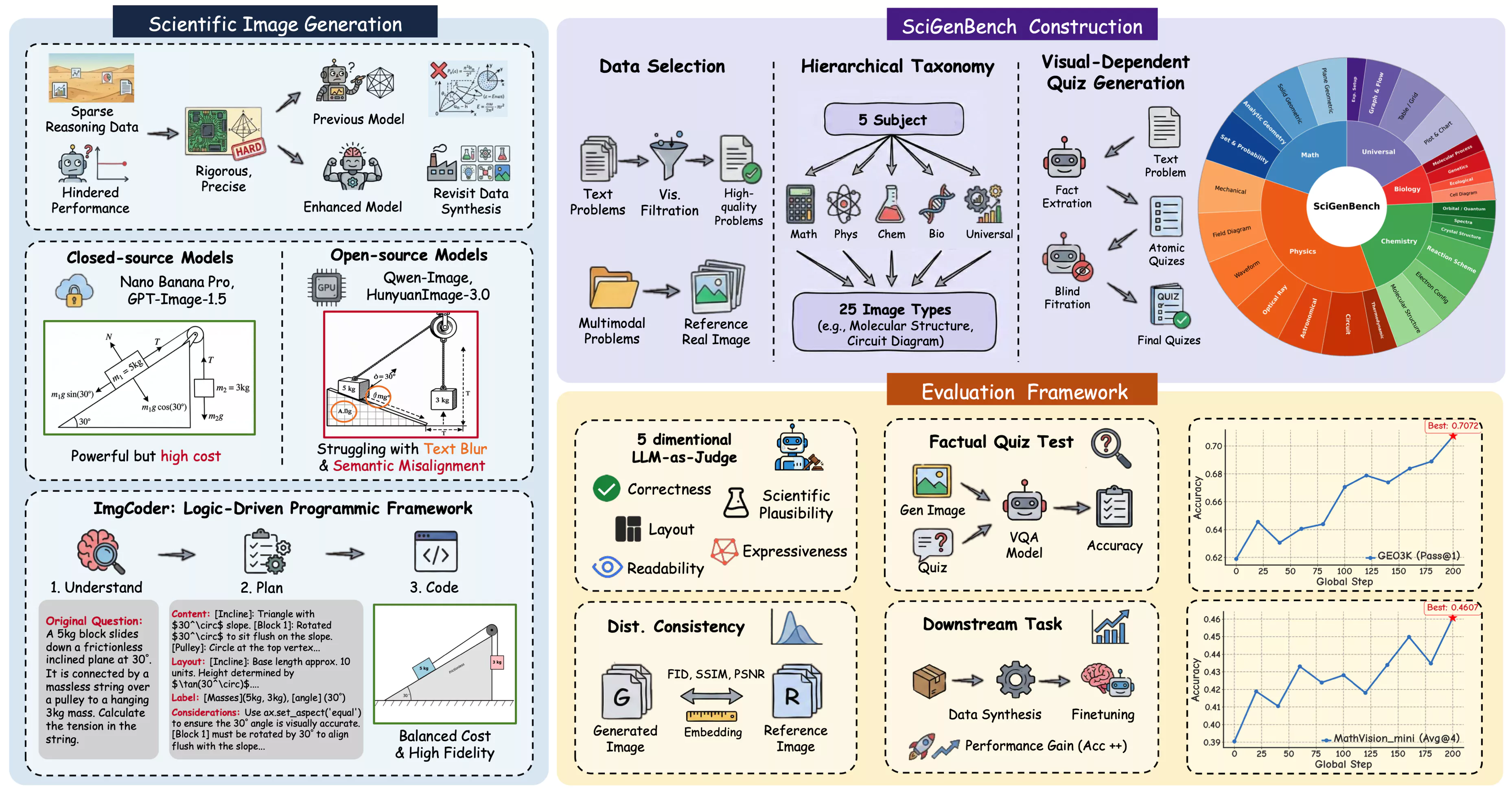
We study scientific image synthesis under two paradigms: pixel-based generation and programmatic synthesis. To improve structural correctness in diagram-heavy scientific domains, we propose ImgCoder, a logic-driven framework that follows an explicit Understand → Plan → Code workflow. Concretely, ImgCoder first parses the problem to extract scientific entities and constraints, then produces an explicit layout and labeling plan, and finally emits executable rendering code (e.g., Python/Matplotlib/TikZ) to deterministically generate the figure. This decoupling of reasoning from rendering improves precision and reduces structure-level hallucinations.
We further introduce SciGenBench to evaluate scientific image synthesis along two axes: Information Utility via Inverse Quiz Validation (Rinv) and Logical Correctness via LMM-as-Judge scores. Together, the benchmark and methodology enable systematic analysis of generation failures and support downstream training with rigorously verified synthetic images.
SciGenBench Leaderboard
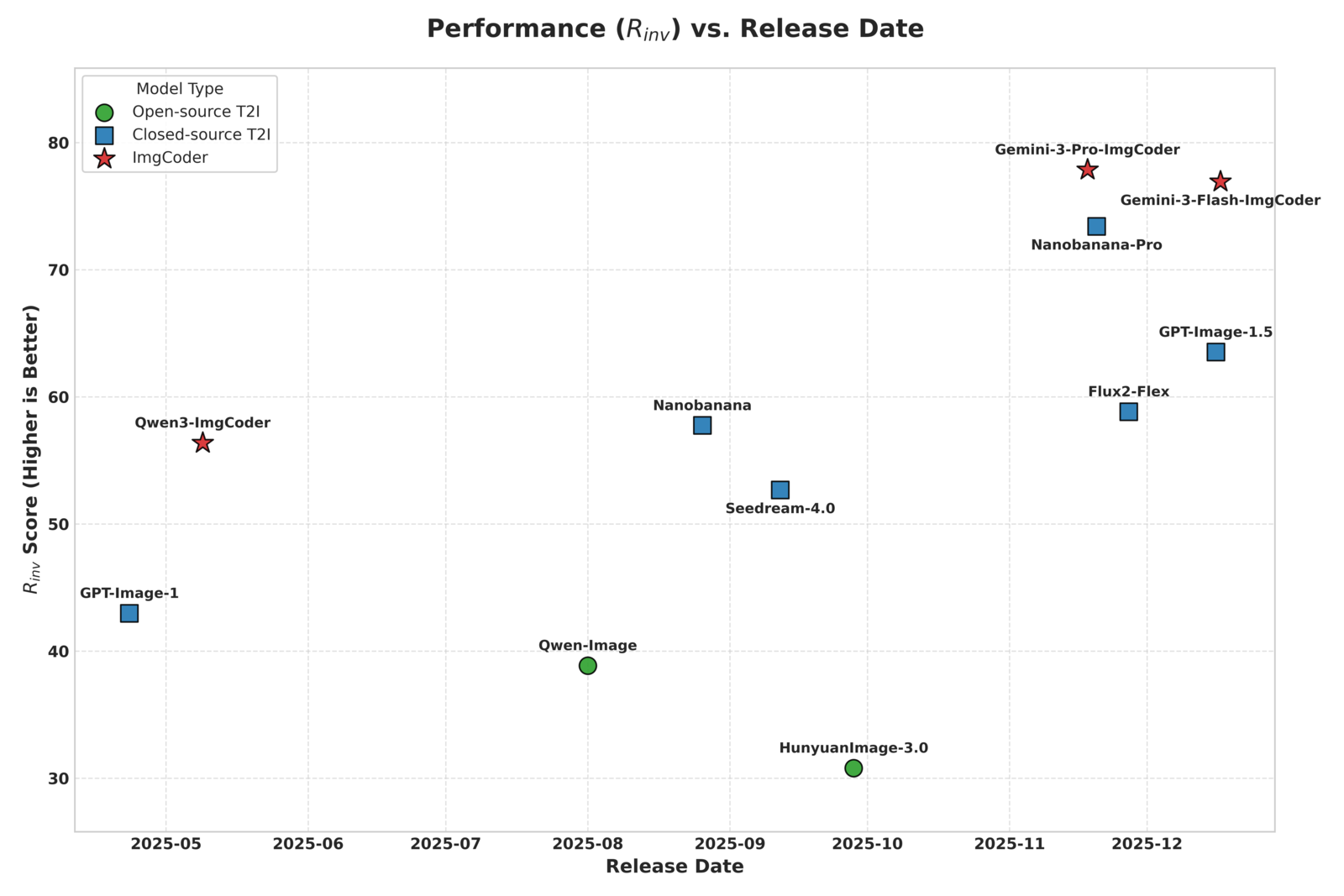
SciGenBench evaluates scientific image generation on two core dimensions: Information Utility via Inverse Quiz Validation (Rinv, ↑) and Logical Correctness via LMM-as-Judge scores (0–2, ↑). Standard metrics are computed on the real-image SeePhys subset (PSNR ↑, SSIM ↑, CLIP ↑, FID ↓).
| Model | Rinv ↑ | C&F | L&P | R&O | SP | E&R | PSNR | SSIM | CLIP | FID ↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| Open-source T2I Models | ||||||||||
| HunyuanImage-3.0 | 30.79 | 0.39 | 0.78 | 1.44 | 0.56 | 0.81 | 12.21 | 0.82 | 25.01 | 93.27 |
| Qwen-Image | 38.86 | 0.24 | 0.70 | 1.48 | 0.30 | 0.76 | 9.63 | 0.78 | 25.02 | 120.42 |
| Closed-source T2I Models | ||||||||||
| GPT-Image-1 | 42.97 | 0.57 | 1.37 | 1.90 | 0.84 | 1.19 | 13.07 | 0.84 | 25.14 | 77.31 |
| Seedream-4.0 | 52.67 | 0.44 | 0.94 | 1.67 | 0.55 | 0.95 | 10.65 | 0.74 | 25.02 | 98.22 |
| Nanobanana | 57.75 | 0.43 | 0.92 | 1.60 | 0.60 | 1.15 | 14.12 | 0.85 | 25.13 | 104.70 |
| Flux2-Flex | 58.83 | 0.48 | 1.06 | 1.70 | 0.67 | 1.20 | 14.11 | 0.85 | 25.10 | 96.74 |
| GPT-Image-1.5 | 63.52 | 0.98 | 1.70 | 1.97 | 1.17 | 1.62 | 14.79 | 0.88 | 25.16 | 112.52 |
| Nanobanana-Pro | 73.41 | 1.59 | 1.87 | 1.98 | 1.72 | 1.93 | 12.02 | 0.81 | 25.01 | 87.72 |
| ImgCoder | ||||||||||
| Qwen3-ImgCoder | 56.38 | 1.21 | 1.30 | 1.62 | 1.39 | 1.29 | 14.71 | 0.86 | 25.21 | 121.55 |
| Gemini-3-Flash-ImgCoder | 76.93 | 1.80 | 1.88 | 1.88 | 1.92 | 1.91 | 14.63 | 0.85 | 25.18 | 117.83 |
| Gemini-3-Pro-ImgCoder | 77.87 | 1.82 | 1.93 | 1.91 | 1.93 | 1.90 | 14.59 | 0.86 | 25.16 | 107.67 |
Judge dimensions: C&F = Correctness & Fidelity, L&P = Layout & Precision, R&O = Readability & Occlusion, SP = Scientific Plausibility, E&R = Expressiveness & Richness.
BibTeX
@article{lin2026scientific,
title={Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility},
author={Honglin Lin and Chonghan Qin and Zheng Liu and Qizhi Pei and Yu Li and Zhanping Zhong and Xin Gao and Yanfeng Wang and Conghui He and Lijun Wu},
journal={arXiv preprint arXiv:2601.17027},
year={2026},
url={https://arxiv.org/abs/2601.17027/}
}